The following criteria can be used for comparing different models which use the same weighting and are fitted to the same data. The notation is:
n: Number of independent measurements considered in the fit
p: Number of fitted parameters
wi: Weight applied to residual of acquisition i
Akaike Information Criterion (AIC)
The Akaike Information Criterion [1] is defined by the formula

If applicable, PKIN uses an adjusted procedure with a second order correction for small sample size (<40) [2]
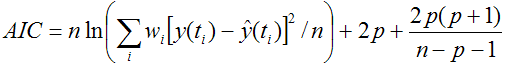
The more appropriate model is the one with the smaller AIC value.
Schwartz Criterion (SC)
The Schwartz Criterion is defined by the formula

The more appropriate model is the one with the smaller SC value.
Model Selection Criterion
Another modified version of the AIC criterion used in the Scientist Software (MicroMath, Saint Louis, Missouri USA) is the Model Selection Criterion

This criterion has the advantage that it is independent of the magnitude of the yi. Opposed to the AIC and the SC the more appropriate model is that with the larger MSC.
F-Test
Two nested models can be compared by an F-test of their sum of squared residuals [3]. The idea is to compare the total sum of squares into a component removed by the simpler model and into a component additionally removed by the more complex model. For each component, the mean square (sum of squares per degree of freedom) is calculated. The residual mean square is an estimate of the variance of the original data. The ratio of the two mean squares is the F-statistic used to test for significance of the variance reduction by the additional parameters, as follows:

where
Q1 represent the weighted residual sum of squares or the simple model with p1 parameters,
Q2 the weighted residual sum of squares of the more complex model with p2 parameters,
p1 < p2
The F-statistics has (p2-p1 ,n-p2) degrees of freedom. If the calculated F is larger than the tabulated value at a specified p value, the reduction of the residual variation by the addition of the (p2 - p1 ) extra parameters of the more complex model is statistically significant. Usually, significance p=0.05.
Note: in MS Excel the Fp(p2-p1 ,n-p2) can be calculated by the function FINV(p;p2-p1;n-p2).
References
1.Akaike, H. A new look at the statistical model identification. IEEE Trans. Automat. Contr 1974, AC19: 716-723.
2.Motulsky H, Christopoulos A. Fitting Models to Biological Data using Linear and Nonlinear Regression. New York: Oxford University Press; 2004.
3.Carson RE, Parameter Estimation in PET, In: M. Phelps JM, and Schelbert H, eds. Positron Emission Tomography and Autoradiography: Principles and Applications for the Brain and the Heart., New York: Raven Press; 1986: 287-346.